이 글은 SimpleMem: Efficient Lifelong Memory for LLM Agents을 읽고 리뷰한 글입니다.
현재는 논문의 일부 내용이 수정되어 작성 시점(2026.01.24)과 상이할 수 있습니다.
배경
LLM은 기본적으로 상태가 없는(stateless)한 특징을 갖고 있습니다. 따라서, 이전 추론 결과가 다음 추론 결과에 영향을 주지 않습니다.
이러한 특성으로 인해, LLM을 그냥 사용하면 대화가 연속적으로 이어지지 못 하는 문제가 발생할 수 있습니다. 즉, 나와 방금 나눈 대화를 기억하지 못 하는 초단기 기억 상실증 같은 모습을 보이는 것입니다.
연구자들은 간단한 방법으로 이 문제를 해결하였습니다. 바로 사용자와 LLM 에이전트 사이의 대화 이력을 별도의 공간(e.g. 메모리)에 저장하고, 매 추론마다 입력 프롬프트에 과거 대화 이력을 주입함으로써 LLM으로 하여금 연속적인 대화가 가능하도록 만든 것입니다.
이와 같은 방법은 연속적인 대화를 가능하도록 하는 매우 직관적으고 효과적인 해결책입니다. 하지만 이는 컨텍스트 길이가 길어지는 문제를 유발합니다. 과거 대화 이력을 프롬프트에 주입함으로 인해, 입력 프롬프트의 길이가 길어지게 되는 것입니다.
늘어난 프롬프트 길이는 부수적인 문제들을 유발합니다. 우선, 입력 프롬프트의 길이가 LLM 모델의 프롬프트 길이 한계(hard limit)을 초과하여 추론이 불가능해지는 문제가 발생할 수 있습니다.
뿐만 아니라, 늘어난 컨텍스트 길이는 추론 시간 증가와 성능 저하를 유발합니다. Databricks의 연구 결과에 따르면, 과도한 컨텍스트 길이는 RAG 시스템의 추론 품질을 오히려 악화시킬 수 있습니다.
실험 결과, 일정 수준까지는 답변을 생성하기 위한 자료의 양이 많아짐에 따라서 답변 품질이 개선되었지만, 일정 수준을 초과한 이후로는 품질이 더 이상 개선되지 않거나 오히려 감소하는 현상이 발생하였습니다. 이러한 현상은 LLM 모델의 종류를 막론하고 일관적으로 관찰되었습니다.
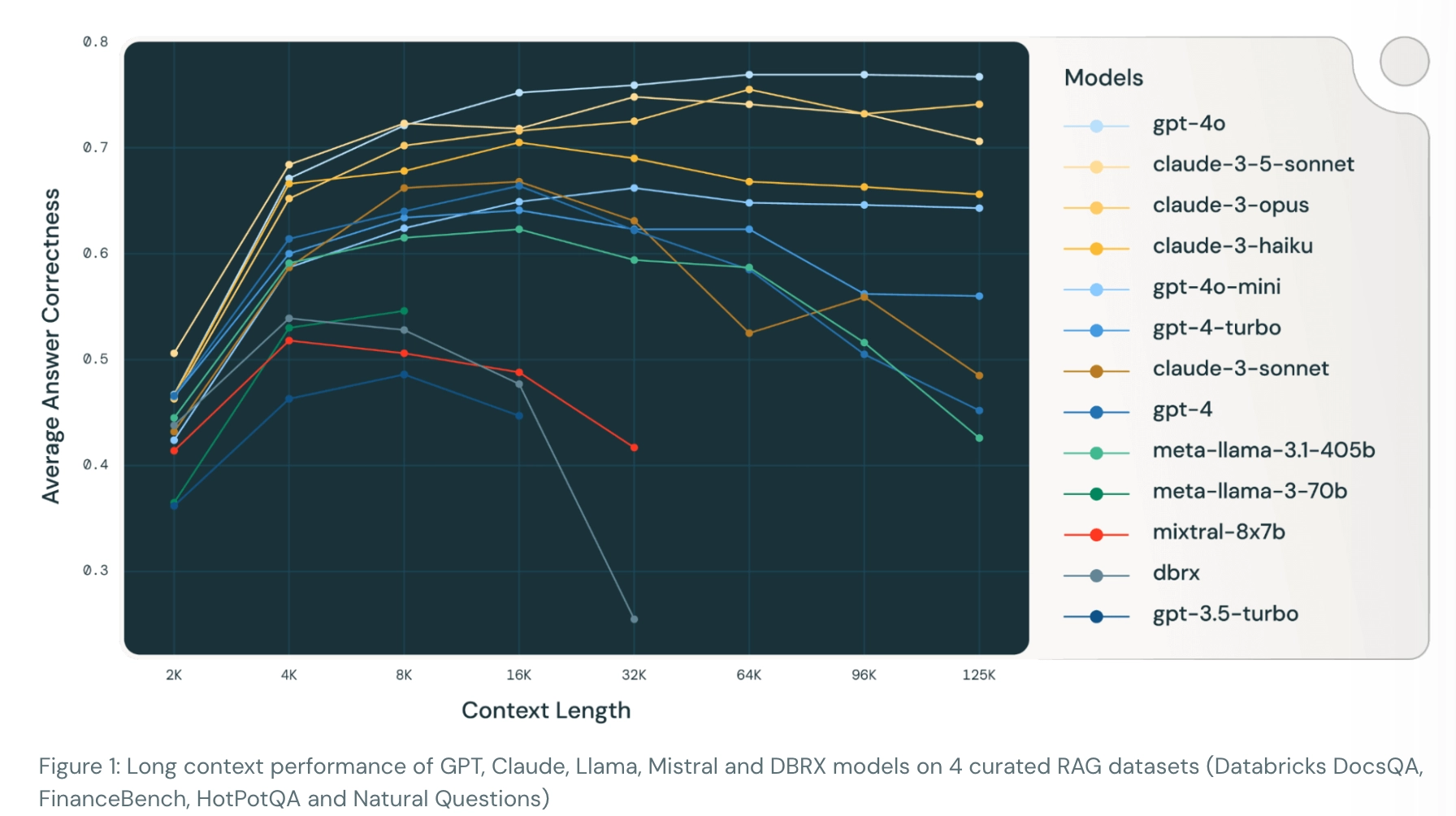
컨텍스트 길이가 과도하게 길어짐에 따라, LLM 모델들은 자신있게 오답을 말하거나(GPT-4), 뜬금없이 저작권 문제 등을 언급하며 답변을 거부하기도 하고(Claude-3-Sonnet), 심지어는 동일한 단어를 끝없이 반복하는 등(Mixtral-instruct)의 이상 현상을 보이기도 하였습니다.

메모리 시스템도 이와 유사한 한계를 갖고 있습니다. 대화가 길어짐에 따라, 입력 프롬프트의 길이도 자연스럽게 늘어나게 됩니다. 이로 인해, 토큰 사용량이 증가하고 성능 저하가 발생할 수 있습니다. 이러한 현상은 대화가 오래 지속될수록 심화됩니다.
논문에서는 이러한 문제를 해결하기 위한 무손실 의미론적 압축 (semantic lossless compression) 방법론을 제안하고 있습니다.
키워드
- 엔트로피 기반 필터링 (entropy-aware filtering)
- 재귀적 메모리 통합 (Recursive Memory Consolidation)
- 적응형 쿼리 인식 검색 (Adaptive Query-Aware Retrieval)
제안 내용
논문에서는 다음과 같은 3단계 파이프라인을 제안합니다.
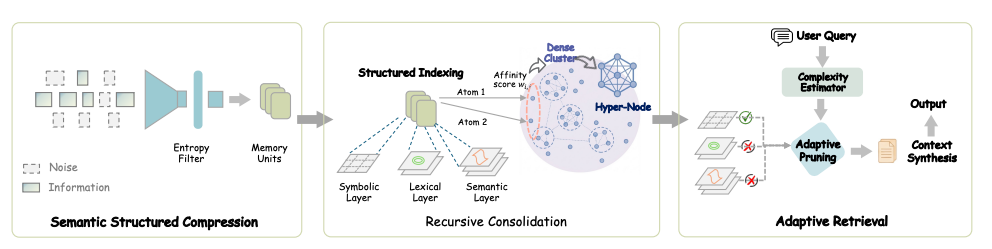
1. 의미론적 구조화 압축 (Semantic Structured Compression)
중요하지 않은 대화는 버리고, 중요한 대화만 메모리에 저장한다.
논문에서는 장기간 쌓이는 대화 메모리의 주된 병목의 원인은 중요하지 않은 대화가 메모리에 과도하게 쌓이는 현상(context inflation)이라고 말합니다. 따라서, 엔트로피라는 개념을 통해 대화의 중요도를 평가하고, 중요하지 않은 대화 기록들을 제거하는 필터링 프로세스를 제안합니다.
정보점수 측정
우선 중요한 대화와 그렇지 않은 대화를 구분하기 위해 대화의 중요도에 해당하는 정보 점수(information score)를 측정합니다. 논문에서는 정보 점수를 다음과 같이 정의합니다.
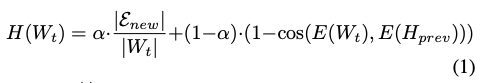
정보 점수($H(W_t)$)는 크게 다음 항목으로 구성됩니다.
- $\frac{|\mathcal{E}_{new}|}{|W_t|}$: 개체의 참신성(entity-level novelty)
- $|\mathcal{E}_{new}|$: 누적 메모리($H_{prev}$)에 아직 등장하지 않은 새로운 엔티티의 개수
- $|W_t|$: 대화 묶음 길이(overlapping sliding window size)
- 즉, 이번 대화 창에서 “새로운 엔티티가 얼마나 많이 등장했는지"를 정규화해 측정하는 항입니다.
- $1 - cos(E(W_t),E(H_{prev}))$: 의미적 차별성(semantic divergence)
- $E(W_t)$: 현재 대화의 임베딩
- $E(H_{prev})$: 과거 메모리의 임베딩
- 두 임베딩이 의미적으로 유사할수록 코사인 유사도는 커지고, 이 항의 값은 작아집니다.
- $\alpha$: 개체의 참신성과 의미적 차별성 사이의 가중치
필터링 적용
다음 과정은 정보 점수에 따른 필터링을 적용하는 단계입니다. 정보 점수가 기준치($\tau_{redundant}$)에 미달하는 경우, 대화에 유의미한 정보가 없다고 판단하여 해당 대화 기록을 버립니다($\varnothing$).

메모리 유닛 ($m_k$) 생성
다음으로 필터링을 거친 대화로부터 메모리 유닛을 생성합니다.
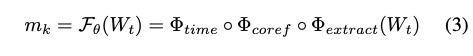
메모리 유닛은 대화 기록을 맥락을 구체화하여 독립적으로 활용하기 좋도록 가공한 결과물입니다. 메모리 유닛 생성은 다음의 세 가지 단계를 거칩니다.
- $\Phi_{extract}(W_t)$: 대화에서 사실 진술만 추출
- $\Phi_{coref}$: 대명사를 구체적인 개체명으로 치환 (ex, He agreed → Bob agreed)
- $\Phi_{time}$: 상대적인 시간을 절대적인 타임스탬프(ISO-8601)로 치환 (ex, next Friday → 2025-10-24)
2. 구조적 인덱싱과 재귀적 메모리 통합 (Structured Indexing & Recursive Memory Consolidation)
메모리를 다양하게 인덱싱하고, 주기적으로 정리해서 효율화 한다
구조화 인덱싱
하나의 메모리 유닛은 다음의 세 가지 방식으로 각각 인덱싱 되어 저장됩니다.
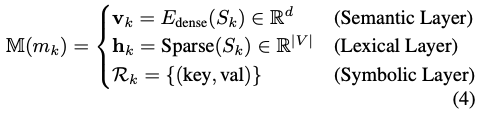
- Semantic Layer: 의미론적 정보를 담기 위한 벡터 임베딩
- Lexical Layer: 주요 키워드를 중심으로 역색인 인덱싱
- Symbolic Layer: 주요 메타데이터를 키-밸류 태그 형태로 인덱싱
이를 통해, 매우 다양한 쿼리 패턴(의미 검색, 키워드 검색, 태그 검색)에 유연하게 대응할 수 있도록 합니다.
재귀적 메모리 통합
정보 점수에 따른 필터링을 적용하더라도, 시간이 지남에따라 메모리가 과도하게 누적될 수 있습니다. 이를 해결하기 위해, 논문에서는 유사한 메모리 유닛을 합쳐서 정리하는 비동기 백그라운드 프로세스를 제안합니다.
우선, 현재까지 저장된 메모리 유닛에 대해, 두 메모리 유닛( $m_i$, $m_j$)이 얼마나 가까운지에 해당하는 affinity score($w_{ij}$)를 측정합니다.
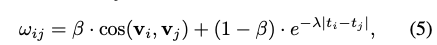
affinity score는 다음의 두 가지 항의 합으로 정의됩니다.
- $cos(v_i,v_j)$: 두 메모리 유닛이 의미적으로 얼마나 유사한가? (semantic relatedness)
- $e^{-\lambda |t_i - t_j|}$: 두 메모리 유닛이 시간적으로 얼마나 인접해있는가? (temporal proximity)
다음으로, 유사한 메모리를 통합(consolidation)합니다.
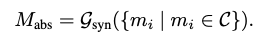
이 과정에서는 affinity score가 일정 수준 이상을 만족하는 유사 메모리 유닛들을 묶고($C$) 이를 LLM 모델을 활용하여 추상되된 메모리 유닛으로 합치는 작업($G_{syn}$)을 수행합니다. 이를 통해, 최종적으로 추상화된 메모리 유닛 $M_{abs}$을 생성합니다.
예를 들어, 오전 8시에 커피를 주문하는 내용의 대화에 대한 기억($m_i$)이 많았다고 하면, 이를 통합하여 “이 유저는 아침에 주로 커피를 마신다"와 같은 추상화된 메모리 유닛으로 압축합니다. 이를 통해, 메모리 공간이 과도하게 늘어나는 것을 방지합니다.
작은 개별 사건에 대한 기억들을 하나의 추상화된 기억으로 합치는 방법론은 이 논문 이전에도 다수의 선행 연구를 통해 보고되었습니다. 대표적으로, 구글과 스탠포드에서 공동 연구로 발표한 Generative Agent 논문에서는 회고(reflection)라는 이름으로 위와 유사한 프로세스를 제안하였습니다.
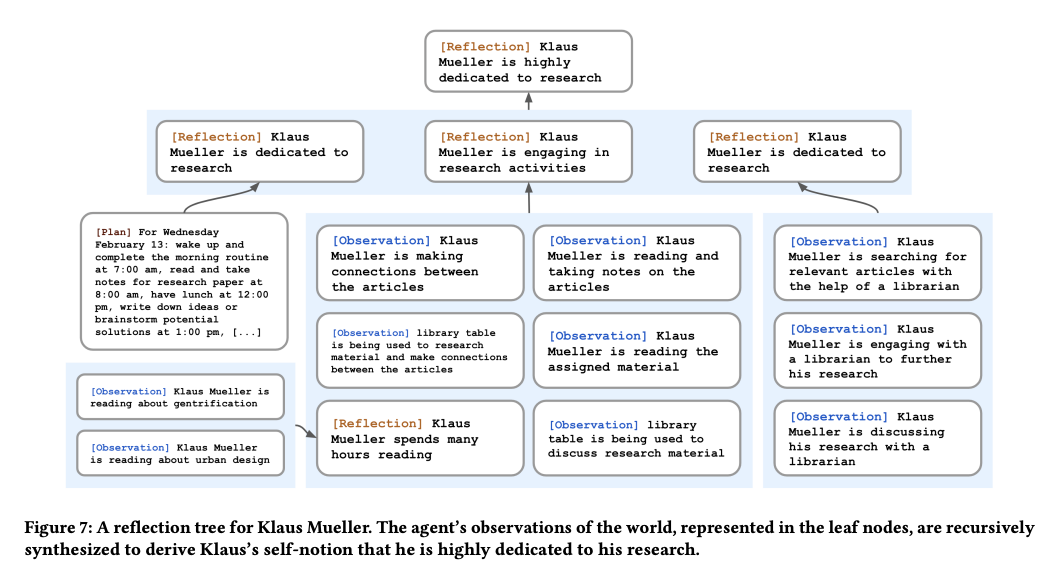
3. 적응형 쿼리 인식 검색 (Adaptive Query-Aware Retrieval)
질문이 단순하면 가볍게 회상, 복잡하면 다양한 메모리를 복합적으로 검사
마지막 단계는 적절한 메모리 유닛을 회상(retrieval)하는 단계입니다.
일반적인 RAG 시스템에서는 유사도/키워드 검색을 통해 고정된 top-k개의 컨텐츠를 불러옵니다. 하지만, 이 논문에서는 질문의 복잡도에 따라서 회상해야 하는 메모리 유닛의 개수가 달라질 수 있음을 지적합니다. 따라서, 논문은 사용자의 질문 복잡도에 따라서, 메모리 회상 개수를 동적으로 조절하는 쿼리 계층을 제안합니다.
Hybrid Scoring Function
논문에서는 주어진 쿼리($q$)에 대해, 메모리 유닛($m_k$)이 얼마나 적합한지에 대한 점수($S(q, m_k)$)를 다음과 같이 정의합니다.
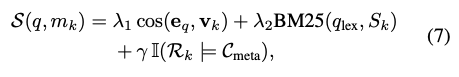
- $\lambda_1 \cos(e_q, v_k)$: 쿼리와 메모리 유닛이 얼마나 의미론적으로 유사한지
- $\lambda_2 \text{BM25}(q_{lex}, S_k)$: 질문에 나온 키워드가 메모리 유닛에 얼마나 등장하는지
- $\gamma I(R_k \models C_{meta})$: 메모리 유닛의 태그($R_k$)가 쿼리에서 추출한 조건(constraint)와 일치하는지
마지막으로, 주어진 질문 복잡도에 따라서 답변 생성을 위해 활용할 메모리 유닛의 개수($k_{dyn}$)를 동적으로 조절합니다.
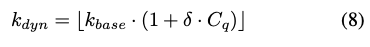
- $k_{base}$: 쿼리 응답에 사용될 최소 메모리 개수
- $C_q$: 주어진 쿼리의 복잡도 (0~1), 매우 간단한 분류기(classifier)로 측정
- 복잡도($C_q$)가 높아질수록 더 많은 메모리를 회상하는 구조로 동작
실험 결과
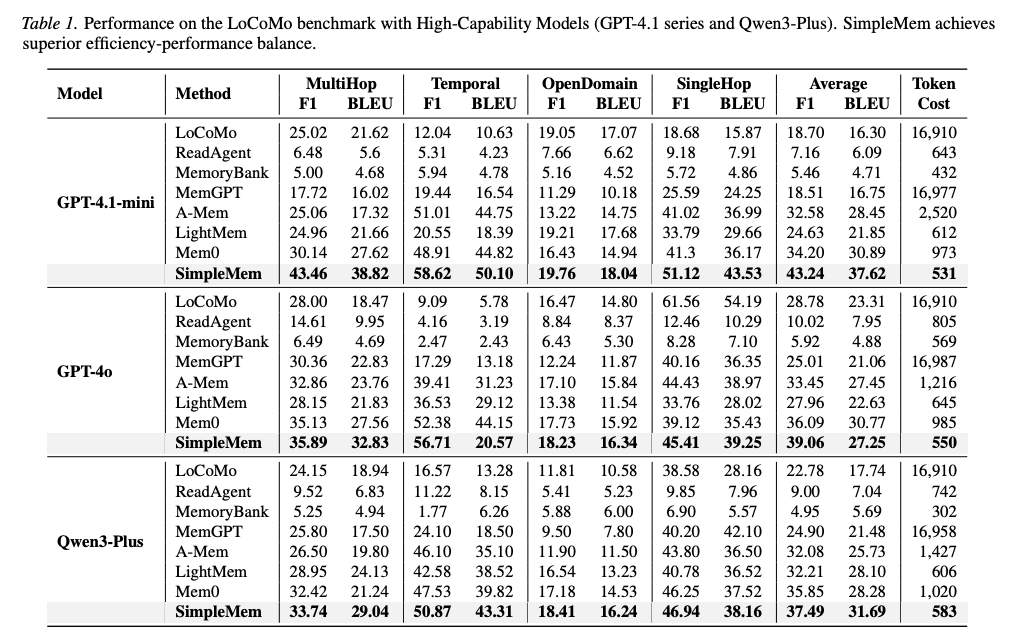
논문은 성능(F1)과 효율(추론 토큰 비용)을 함께 비교했을 때, SimpleMem이 기존 메모리 방식 대비 더 나은 균형점을 만든다고 주장합니다.
벤치마크
논문은 LoCoMo와 LongMemEval-S를 중심으로 성능을 평가합니다.
LoCoMo는 200~400턴 길이의 대화를 포함하는 장문 맥락 벤치마크이며, 총 1,986개의 질문으로 구성되어 있습니다. LongMemEval-S는 훨씬 긴 상호작용 히스토리에서 필요한 정보를 정확히 찾아내는 능력을 평가하도록 설계되어 있고, 여기서는 gpt-4.1-mini를 활용한 LLM-as-a-judge 방식으로 정답 여부를 CORRECT/WRONG으로 판정합니다.
실험 결과
실험에서 저자들은 LoCoMo 기준 평균 F1이 26.4% 개선되었고, 추론 시 토큰 사용량은 full-context 대비 최대 30배까지 감소했다고 보고합니다. 특히, 기존 SOTA(최고 성능) 모델인 Mem0보다 뛰어난 성능을 보였습니다.