This post is a review of SimpleMem: Efficient Lifelong Memory for LLM Agents.
Some parts of the paper have been updated after this post was written (2026-01-24), so there may be differences from the version discussed here.
Background
LLMs are fundamentally stateless. As a result, previous inference outputs do not directly affect later outputs.
Because of this property, a plain LLM can fail to maintain continuity in long conversations. In other words, it may look like short-term memory loss, where it cannot remember what was just discussed.
Researchers addressed this with a straightforward idea: store conversation history between the user and the LLM agent in a separate memory space, then inject relevant history into the prompt at each inference step so the model can sustain continuity.
This approach is intuitive and effective, but it introduces context-length growth. As historical exchanges are added into the prompt, input length naturally becomes longer.
Longer prompts cause secondary issues. First, prompt length can exceed the model’s hard context limit, making inference impossible.
In addition, longer context increases latency and can hurt quality. According to Databricks research, excessive context can degrade RAG performance.
Their experiments show that quality improves up to a point as more supporting context is added, but beyond that point quality plateaus or even drops. This pattern appears consistently across different LLM families.
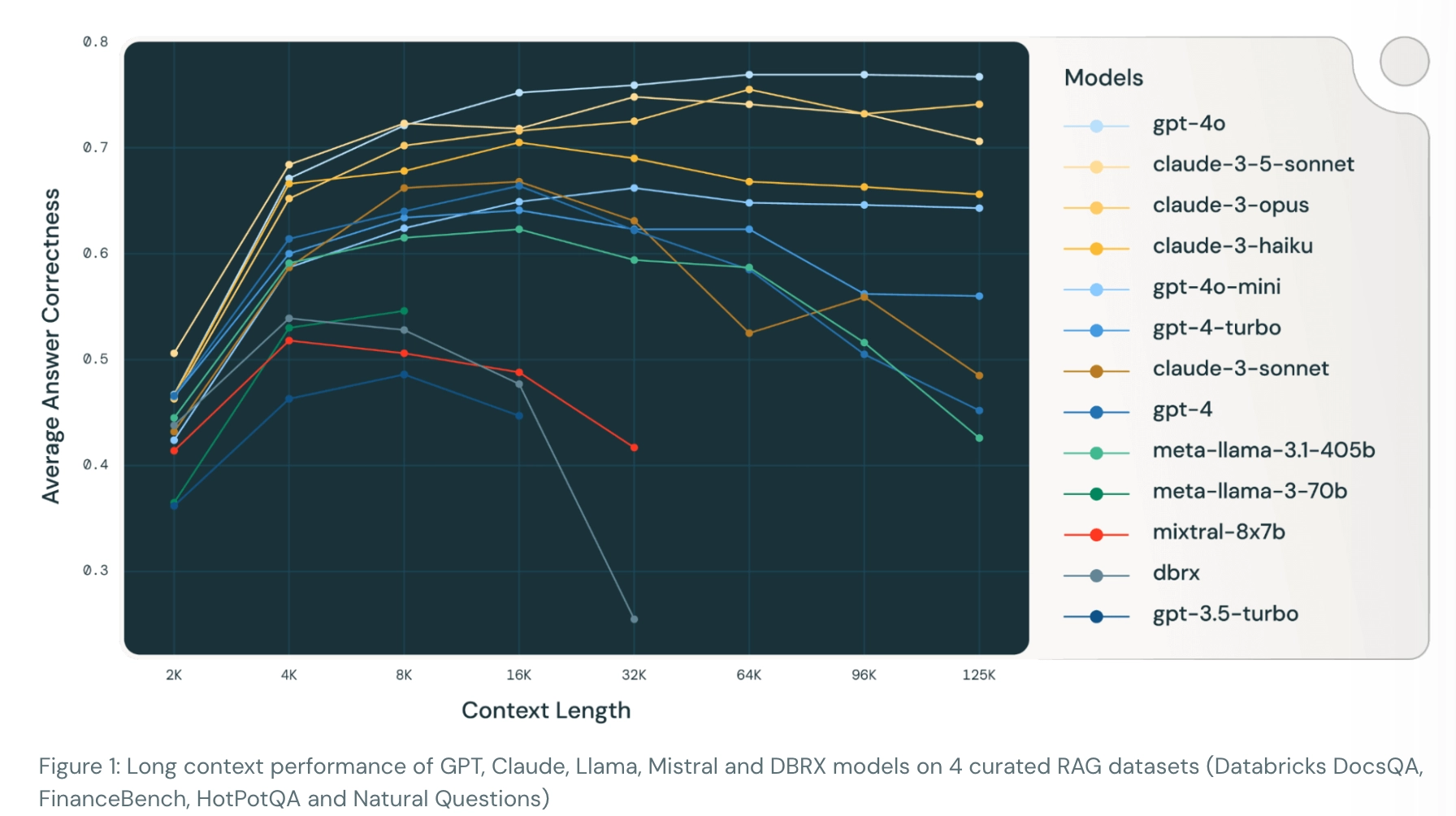
As context grows too large, models may show abnormal behaviors: confidently giving incorrect answers (GPT-4), refusing to answer with unrelated copyright concerns (Claude-3-Sonnet), or repeating the same tokens endlessly (Mixtral-instruct).

Memory systems face a similar limitation. As interactions continue, the prompt grows, token usage rises, and performance can drop. The effect compounds over long sessions.
The paper proposes a semantic lossless compression framework to address these issues.
Keywords
- Entropy-aware filtering
- Recursive Memory Consolidation
- Adaptive Query-Aware Retrieval
Proposed Method
The paper introduces a three-stage pipeline:
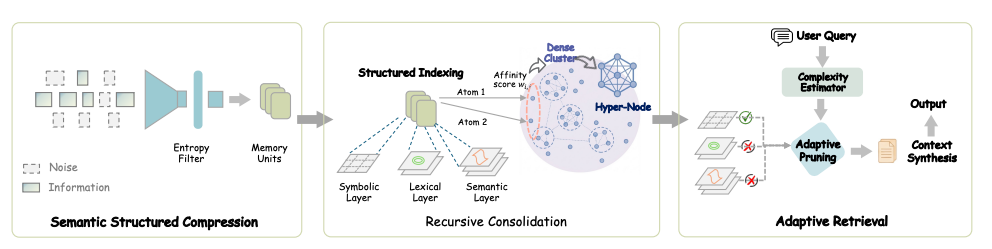
1. Semantic Structured Compression
Discard unimportant dialogue and keep only informative content.
The paper argues that the main bottleneck in long-term conversational memory is context inflation: too much low-value content accumulates over time. To address this, it proposes a filtering process that scores the informativeness of each window using entropy-inspired signals.
Information score
To separate important dialogue from unimportant dialogue, the method estimates an information score. The paper defines it as:
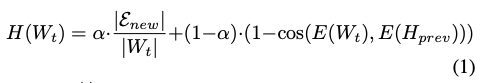
The information score ($H(W_t)$) is composed of the following terms:
- $\frac{|\mathcal{E}_{new}|}{|W_t|}$: entity-level novelty
- $|\mathcal{E}_{new}|$: the number of entities not seen in accumulated memory ($H_{prev}$)
- $|W_t|$: the dialogue window length (overlapping sliding window size)
- In short, this term measures how much genuinely new entity-level information appears in the current window.
- $1 - cos(E(W_t),E(H_{prev}))$: semantic divergence
- $E(W_t)$: embedding of the current dialogue window
- $E(H_{prev})$: embedding of past memory
- If the two are semantically similar, cosine similarity increases and this divergence term decreases.
- $\alpha$: weighting factor between entity novelty and semantic divergence
Filtering
The next step applies threshold-based filtering using the information score. If the score falls below a threshold ($\tau_{redundant}$), the window is treated as non-informative and dropped ($\varnothing$).

Memory unit ($m_k$) construction
From the filtered dialogue, the system constructs memory units.
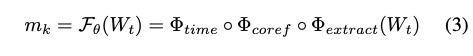
A memory unit is a context-grounded and reusable representation of dialogue content. Construction consists of three transformations:
- $\Phi_{extract}(W_t)$: extract factual statements from dialogue
- $\Phi_{coref}$: resolve pronouns into concrete entities (e.g.,
He agreed->Bob agreed) - $\Phi_{time}$: convert relative time into absolute ISO-8601 timestamps (e.g.,
next Friday->2025-10-24)
2. Structured Indexing & Recursive Memory Consolidation
Index memory in multiple ways and periodically consolidate it for efficiency.
Structured indexing
Each memory unit is stored through three complementary index views:
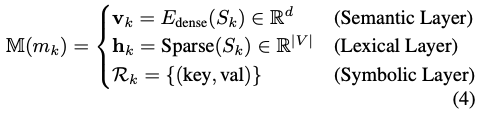
- Semantic Layer: dense vector embedding for semantic matching
- Lexical Layer: inverted-index style keyword retrieval
- Symbolic Layer: key-value metadata tags for structured constraints
This allows the system to handle diverse query patterns (semantic, keyword, and metadata-based search) more robustly.
Recursive memory consolidation
Even with filtering, memory can still accumulate excessively over time. To control this, the paper proposes an asynchronous background consolidation process that merges similar memory units.
First, for stored memory units, it computes an affinity score ($w_{ij}$) between two units ($m_i$, $m_j$):
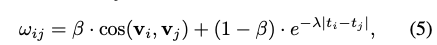
The affinity score combines:
- $cos(v_i,v_j)$: semantic relatedness between two memory units
- $e^{-\lambda |t_i - t_j|}$: temporal proximity between two memory units
Then similar units are consolidated:
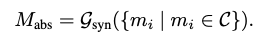
In this step, units with affinity above a threshold are grouped ($C$), and an LLM-based synthesis function ($G_{syn}$) merges them into abstract memory units. The final output is an abstracted unit $M_{abs}$.
For example, if there are many memories about ordering coffee at 8 a.m., the system can compress them into an abstract unit like “the user usually drinks coffee in the morning,” preventing uncontrolled memory growth.
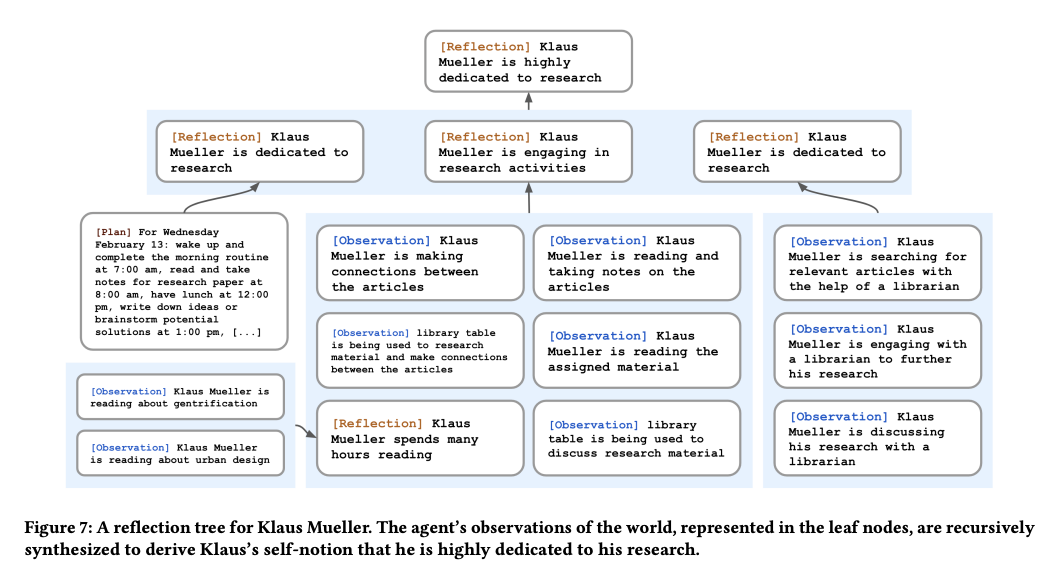
This idea of merging small episodic memories into a more abstract representation also appears in prior work. A representative example is Generative Agents, which uses a similar process called reflection.
3. Adaptive Query-Aware Retrieval
Use lightweight recall for simple questions, and broader multi-view retrieval for complex ones.
The final stage retrieves memory units for response generation.
In standard RAG systems, top-k content is usually fetched with a fixed retrieval depth. This paper points out that the number of units needed varies by query complexity. It therefore proposes a query layer that dynamically adjusts retrieval depth.
Hybrid Scoring Function
The paper defines a relevance score $S(q, m_k)$ between query ($q$) and memory unit ($m_k$):
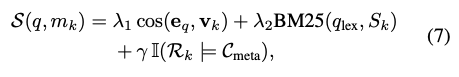
- $\lambda_1 \cos(e_q, v_k)$: semantic similarity between query and memory unit
- $\lambda_2 \text{BM25}(q_{lex}, S_k)$: lexical overlap between query keywords and the memory unit
- $\gamma I(R_k \models C_{meta})$: whether memory tags ($R_k$) satisfy query constraints ($C_{meta}$)
Finally, the number of recalled units ($k_{dyn}$) is adjusted dynamically based on query complexity:
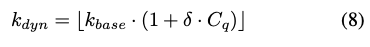
- $k_{base}$: minimum memory count used for answer generation
- $C_q$: query complexity in [0, 1], estimated by a lightweight classifier
- Higher complexity ($C_q$) leads to larger retrieval depth
Experiments
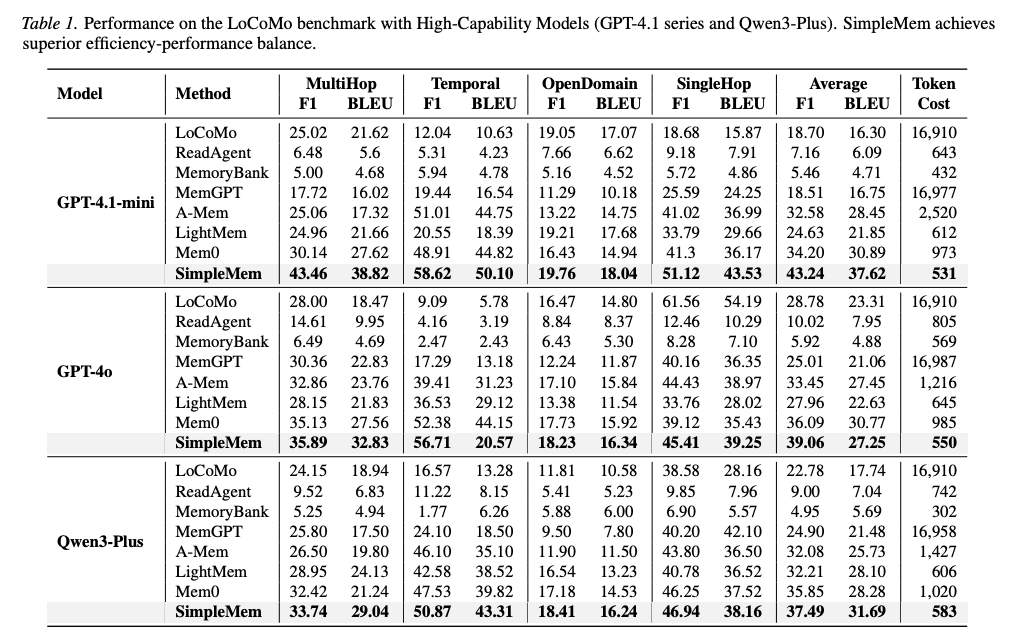
The paper claims that, when considering both effectiveness (F1) and efficiency (inference token cost), SimpleMem achieves a better trade-off than prior memory approaches.
Benchmarks
The evaluation focuses on LoCoMo and LongMemEval-S.
LoCoMo is a long-context conversational benchmark with 200-400 turns and 1,986 evaluation questions. LongMemEval-S is designed to test precise retrieval over extremely long interaction histories. For LongMemEval-S, the paper uses an LLM-as-a-judge protocol with gpt-4.1-mini, labeling outputs as CORRECT or WRONG.
Results
The authors report an average F1 improvement of 26.4% on LoCoMo and up to 30x lower inference-time token usage compared to full-context baselines. They also report stronger performance than the previous SOTA memory framework Mem0.